import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
xData = [1, 2, 3, 4, 5, 6, 7] # 잃한 시간
yData = [25000, 55000, 75000, 110000, 128000, 155000, 180000] # 하루 매출
#W는 Weight(가중치). -100에서 100사이의 랜덤값
W = tf.Variable(tf.random.uniform([1], -100, 100))
# b는 bias y절편
b = tf.Variable(tf.random.uniform([1], -100, 100))
#placeholder라는 하나의 틀
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# 가설식. H는 가설 (Hypothesis) 의 약자
H = W * X + b
#비용함수. 비용(cost) 는 (가설값-실제값)의 제곱의 평균 (reduce_mean함수)
cost = tf.reduce_mean(tf.square(H - Y))
# 중요! 경사 하강 알고리즘에서 한번에 얼만큼 점프할건지. step의 크기. 너무 작아도, 너무 커도 좋지 않다. 프로그래머가 정한다.
a = tf.Variable(0.01)
optimizer = tf.train.GradientDescentOptimizer(a) #경사하강 (GradientDescent)
# 학습방법 : 비용함수를 가장 적게 만드는 방법으로 학습
train = optimizer.minimize(cost)
# 변수 초기화
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 학습이 일어나는 부분: 5000번 돌린다.
for i in range(5001):
sess.run(train, feed_dict={X: xData, Y: yData})
if i % 500 == 0:
print(i, cost, sess.run(cost, feed_dict={X: xData, Y: yData}), sess.run(W), sess.run(b))
# 8시간 일하면 얼마 벌까?
print(sess.run(H, feed_dict={X: [8]}))
DNS Zone Takeover 취약점은 그 이름 그대로 DNS Zone 자체가 테이크오버 (탈취) 되는 취약점이다. 자신이 운영하던 도메인이 어느새 다른 사람에게 탈취당할 수도 있다는 것이다.
DNS Zone Transfer 등은 주로 자기가 직접 DNS 서비스를 운영하는 경우에 많이 발생(DNS 서버 관리자의 실수) 하는데 DNS Zone Takeover 오히려 클라우드 서비스를 이용할 경우에 많이 발생한다. 왜 그런지는 아래에서 설명하겠다.
원리
이 취약점을 이해하려면 먼저 도메인 관리의 위임관계를 이해해야 한다. Zone은 상위 DNS 서버에서 위임을 받아서 운영한다. 이때 중요한 점은 상위 DNS 서버에서는 이 Zone은 이 하위 서버에게 위임한다고 설정이 되어 있어야 하고, 하위 DNS 서버에서는 이 Zone은 내가 관리한다고 설정이 되어 있어야 한다. 양쪽 모두 올바르게 설정이 되어 있어야 제대로 동작하는 구조인 것이다.
그런데 다음과 같은 시나리오를 상상해보자. 상위 DNS 서버의 설정은 남아 있는데 어느날 하위 DNS 서버의 설정은 없어졌다고 생각해보자. 그러면 해당 도메인은 아무도 주인이 없는 상태가 된다. 상위 DNS 서버에 문의했더니 이 서버에게 물어봐라는 답변은 돌아온다. 그런데 그 하위 DNS 서버에 물어보면 나는 그 도메인 몰라라고 대답하는 상태인 것이다. 이런 상태일 때, 어떤 자가 하위 DNS 서버에게 “그 도메인, 내가 관리하게 해주세요 ” 라고 신청해서 OK를 받았다고 하자. 그러면 그 뒤부터는 해당 도메인을 문의하면 그 “어떤 자” 가 설정한 데이터를 응답해준다. 이 “어떤 자”는 해당 도메인을 마음대로 설정할 수 있게 되었다. 탈취에 성공한 것이다.
위 시나리오가 이 취약점의 원리를 대략적으로 설명한 것이다. 어느 날 갑자기 하위 DNS 서버의 설정이 없어졌다고 했는데, 의외로 종종 발생한다. 주로 어떤 도메인이 필요없어 졌는데하위 DNS 서버에서만 정보를 삭제하고, 상위 DNS 서버에서 정보를 삭제하는 것을 잊어버리는 경우다. 이 때, 이 하위 DNS 서버가 AWS의 Route53 같은 도메인 서비스의 서버였다고 생각해보자. Route53 은 대다수의 사용자가 동일한 서버를 이용하고 이용도 아주 편리하다. 위의 시나리오에서 삭제된 도메인을 내가 관리하게 해주세요 라고 신청하는 것은 간단하게 할 수 있다.
임팩트
이 취약점으로 인해 발생하는 임팩트는 꽤 크다. 해당 도메인으로 온갖 나쁜 짓을 할 수 있기 때문이다. 이 도메인이 어떤 회사의 도메인이라면, 고객들은 기본적으로 그 도메인을 보고 신뢰하기 때문에 피싱에 이용될 경우 피해가 막대해질 수 있다. 또한, 웹 어플리케이션의 방어 메커니즘을 우회할 가능성도 있다. 예를들어, 해당 도메인의 서브도메인만 사용자인증정보에 접근 가능하다라는 조건을 우회할 수 있어 크로스 사이트 스크립팅 등에 악용될 수 있다.
발견
이 취약점을 발견하는 법을 살펴보겠다. 좀 더 정확히는 탈취될 수 있는 상태의 도메인을 발견하는 법이다. 아주 간단하다. dig 툴을 써서 해당 도메인의 정보를 문의했을 때 돌아오는 상태 코드를 보자. SERVFAIL 이 발생했다면 꽤 가능성이 있다고 볼 수 있다. (SERVFAIL 이라고 반드시 다 이 취약점이 해당되는 것은 아니다) 그리고 다음으로는 해당 도메인의 관리가 클라우드 서비스의 DNS 서버에 위임되어 있는지를 체크해보면 좀 더 확률이 상승한다.
대처
그렇다면 이 취약점은 어떻게 해결할 수 있을까? 이 취약점은 상위 DNS 서버와 하위 DNS 서버의 설정 불일치가 원인이었다. 좀 더 구체적으로는 상위 DNS 서버에 위임설정이 남아있는 것이 원인이었다. 따라서 상위 DNS 서버에서 해당 도메인의 위임정보를 삭제하면 해결된다.
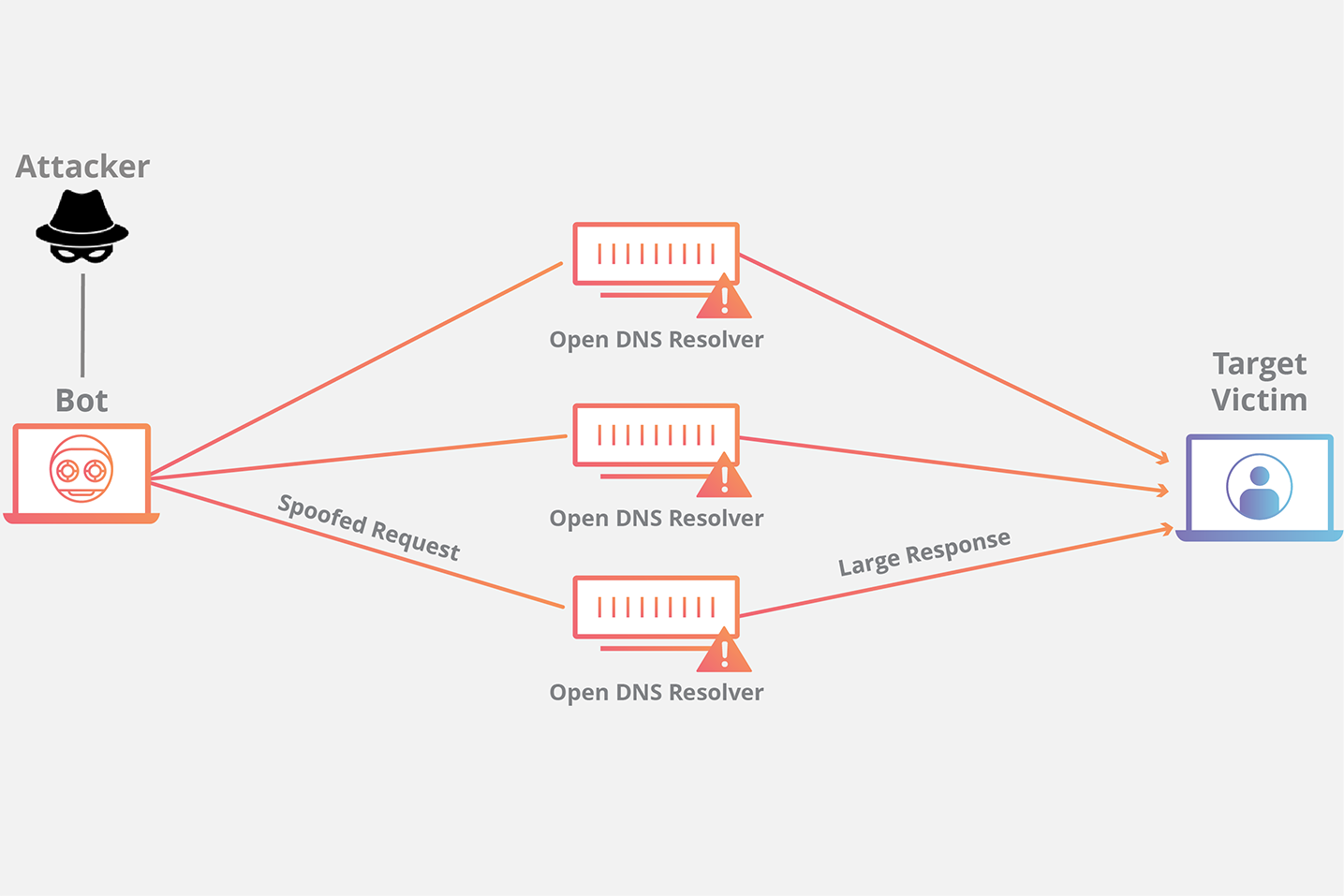
오픈리졸버란 어떤 유저로부터의 DNS요청이던 받아들여서 응답을 해주는 DNS 캐시 서버(full service resolver, 이하 DNS서버)를 말한다. DNS 서버를 운용할 때는 허용된 유저에게만 응답을 해주도록 하는 것이 일반적이다. 그러나 서버의 설정이 잘못된 경우 오픈리졸버가 되어버릴 수도 있다. 오픈리졸버 상태가 되면 자신도 모르게 DNS 증폭(amplification) 공격에 가담할 수 있으므로 주의해야 한다.
DNS증폭 공격이란 dos공격의 일종으로 공격자가 공격 타겟에게 대량의 DNS응답을 보내 타겟의 자원을 고갈시켜 가동 불능상태로 만드는 공격방법이다. 이 공격에는 다수의 오픈리졸버가 이용된다. 공격자는 ip주소를 공격 타겟의 ip주소로 바꾼 DNS요청을 다수의 오픈리졸버에게 보낸다. 그러면 오픈리졸버는 DNS요청 메세지에 적혀있는 ip주소(공격 타겟의 ip주소)로 응답을 보내게 된다. 공격에 가담하는 오픈리졸버가 많으면 많을수록 공격의 효과도 좋다. 또한 DNS응답의 사이즈가 클수록 효과가 좋다. 자원을 더 빨리 고갈시킬 수 있기 때문이다. 그래서 공격자는 일부러 DNS응답의 크기가 커지도록 하는 테크닉을 사용한다 (EDNS0 과 같은 메세지 사이즈 제한을 극복하기 위한 기술이나 DNSSEC 과 같은 보안관련 기능을 써서 메세지 사이즈를 키운다). 이 공격의 이름이 DNS증폭 공격인 이유이다.
DNS 증폭공격(source: cloudflare)
클라우드 서비스를 이용할 때 자신의 DNS서버가 오픈 리졸버가 되어 DNS 증폭 공격에 가담하게 되면 클라우드 서비스 제공 회사로부터 경고 (알람) 메일이 도착하는 경우도 있다.
그러면 DNS서버가 오픈리졸버인지를 체크하는 방법에 대해 설명하겠다.
다음 사이트를 방문해서 입력폼에 DNS서버의 ip주소를 입력하면 오픈리졸버인지 확인할 수 있다.
혹은 위 사이트에서 안내해주는대로 dig 커맨드를 사용해서 확인할 수도 있다. @1.2.3.4부분을 테스트하고 싶은 DNS서버의 ip주소로 변경하면 된다. 커맨드 실행 결과에 open-resolver-detected 가 표시된다면 그 서버는 오픈리졸버인 상태이다.
dig +short test.openresolver.com TXT @1.2.3.4
(replace 1.2.3.4 with the IP address or domain name of the DNS server you are testing)
원리는 다음과 같다. test.openresolver.com 도메인의 txt레코드에는 open-resolver-detected 라는 문자열이 설정되어 있다. 테스트하고 싶은 서버에게 이 도메인의 txt레코드를 물었을 때 응답이 있다면 이 서버는 임의의 유저의 요청에도 응답했다는 것이므로 오픈리졸버라고 판단이 가능하다.
혹시 자신이 운영하는 서버가 오픈리졸버라는 것을 알았다면 공격에 악용되기 전에 빨리 수정하도록 하자.
이 취약점은 DNS의 Zone 전송 요구를 이용해 도메인 정보를 수집하는 취약점 또는 공격방법이다. DNS Zone 정보를 관리하는 DNS 권위서버(Authoritative Server) 가 자신의 Zone 정보를 아무한테나 알려줄 때 발생한다. 원래 이 것은 가용성을 위해서 복수의 DNS 권위 서버를 운영할 때, 이 권위 서버들 사이에서 Zone 정보의 복사(동기화) 를 위해 사용된다. 그렇지만 설정 미스로 인해 요청을 보낸 송신측을 인증하지 않는 경우에는 자신의 Zone 정보가 모두 노출되어 버린다. Zone 에는 DNS설정에 관한 모든 것이 적혀있기 때문에 공격자가 이 정보를 입수하면 타겟의 도메인이나 네트워크 구성에 대해 많은 것을 알 수 있다.
위의 커맨드를 설명하자면, 먼저 dig 커맨드 뒤에 AXFR 이라는 것이 붙어있다. 이 것은 DNS 쿼리 타입의 하나로 Secondary DNS 서버가 Primary DNS 서버에게 보내는 쿼리이다. Zone 정보를 처음부터 끝까지 보내달라는 의미이다. 참고로 차분만 보내달라는 의미로는 IXFR 이라는 것이 있다.
이어서 나머지 부분 Zone Apex 와 DNS 네임 서버의 도메인을 조사하는 방법에 대해 설명하겠다.
Zone Apex?
Zone Apex 란 해당 DNS Zone의 정점인 도메인을 의미한다. 루트 도메인, 또는 네이키드 도메인이라고 부르기도 하는 것 같다. apex 라는 영어단어가 꼭대기, 정점을 의미하므로 한국어로 번역하자면 존 정점, 존 꼭대기 등이 될 것 같다. 이 블로그에서는 그냥 Zone Apex 라는 단어 그대로 사용하려고 한다.
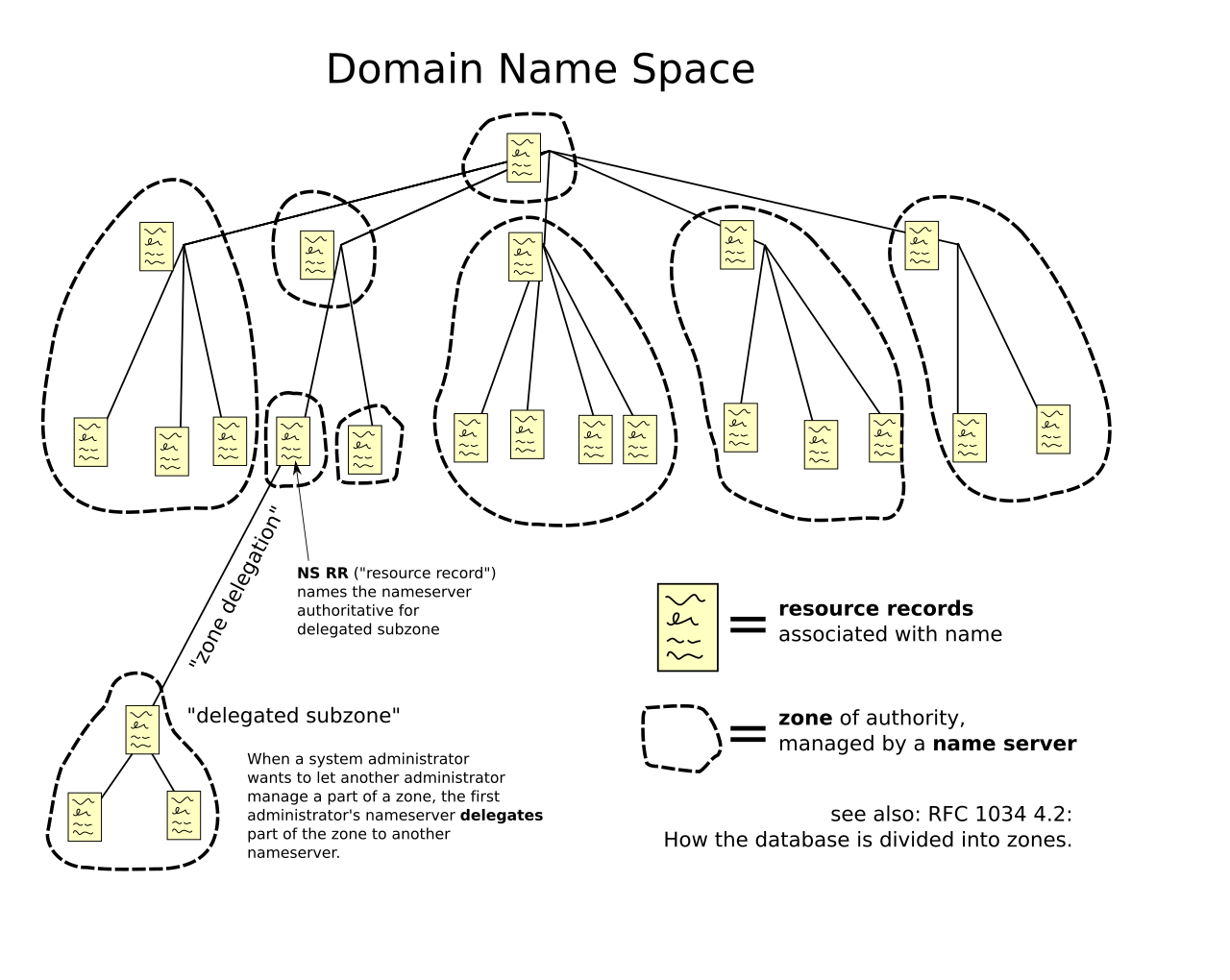
Zone Apex를 이해하기 위해서는 먼저 DNS Zone이 무엇인가를 알아야 한다. DNS Zone 에
대해서는, 자세하게 설명하려면 꽤 길어지지만 간단히 설명해보겠다. 아래의 이미지는 위키피디아에서 퍼온 이미지이다. DNS 는 아래 이미지처럼 트리 구조로 구성되어 있다. 가장 최상위에 루트 도메인 (점(.)으로 표기한다) 이 있고, 그 하위에 .com , .net 등의 최상위 도메인(Top–level domain, TLD)이 있다. 그리고 그 하위에는 example.com 등의 도메인, 또 그 하위에는 aaa.example.com 가 있는 등이다.
이 때, 하위 도메인의 관리는 하위 DNS 서버에 맡기는 (위임하는) 구조로 이 된다. 예를 들자면 루트 도메인(.)을 관리하는 서버는 그 하위인 .com 의 관리를 특정 DNS 서버에 위임한다. 그리고 .com을 관리하는 DNS 서버는 그 하위 도메인인 example.com 도메인을 example.com DNS 서버에 위임한다. example.com 도메인을 관리하는 서버는 aaa.example.com, bbb.example.com 등, example.com 의 하위 도메인에 대해서 권한을 가진다.하위 도메인을 직접 관리할 수도 있고, 별도 DNS 서버에 위임할 수도 있다. 이처럼 각 DNS 서버에서 도메인이 관리되는 영역을 DNS Zone이라고 한다. 위의 그림에서 점선으로 표시된 부분이다. 그리고 해당 Zone 안에서 최상위(정점) 도메인을 Zone Apex라고 한다. 예를들어, example.com 의 Zone Apex는 example.com 이다.
어떤 도메인의 Zone Apex를 알아보는 방법이 있다. 여기서도 dig 커맨드를 사용한다.
dig {도메인명} SOA
SOA 라는 DNS 의 리소스 레코드를 지정하면 해당 도메인의 Zone Apex 를 알 수 있다. 예를 들어, 이 블로그의 도메인인 jaewoongmoon.wordpress.com 를 대상으로 위의 커맨드를 실행해보면 다음과 같은 결과를 볼 수 있다.
AUTHORITY SECTION 에 나오는 도메인이 Zone Apex이다.
좀 더 간단한 결과를 원한다면 다음 커맨드를 사용한다.
dig +noall +authority +answer {도메인명} SOA
결과는 다음과 같다.
jaewoongmoon.wordpress.com. 148 IN CNAME lb.wordpress.com.
wordpress.com. 60 IN SOA ns1.wordpress.com. mmmmmm.gmail.com. 2005071858 14400 7200 604800 60
네임 서버의 도메인은 어떻게 알아내지?
네임서버는 어떻게 알아볼 수 있을까? 역시 dig 를 활용한다. 이번에는 NS 리소스 레코드를 지정한다. NS 리소스 레코드는 Zone Apex 도메인에만 지정할 수 있다. 그러므로 순서상으로는 SOA 리소스 레코드로 Zone Apex 도메인을 알아낸 후에 Zone Apex 도메인을 대상으로 NS 레코드를 질의하면 된다.
처음의 체크 커맨드에 위에서 알아본 정보를 적용해보면 이렇게 된다. (네임서버가 4개 이므로 네 개의 커맨드를 실행할 수 있다. )
dig AXFR wordpress.com @ns1.wordpress.com
참고로 위 커맨드의 실행 결과는 다음과 같다.
$ dig AXFR wordpress.com @ns1.wordpress.com.
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.amzn2.2 <<>> AXFR wordpress.com @ns1.wordpress.com.
;; global options: +cmd
; Transfer failed.
예상했던 결과이지만 실패했다고 나온다. 그러나 만약 네임서버의 설정에 문제가 있어서 상대방을 제대로 인증하지 않을 경우에서는 위의 AXFR 전송 여청이 성공하여 zone 정보가 모두 노출되어 버린다. 실제로 인터넷 상에는 이런 잘못된 설정으로 운영되는 서버가 있다. 실제로 체크해본바, 이 취약점은 AWS와 Azure같은 클라우드 벤더의 서비스에서는 볼 수 없었고, 도메인 서비스를 제공하는 중소기업이나 혹은 직접 네임서버를 운영하는 경우에 많이 볼 수 있었다.
웹 프로그래머 시절에는 본인이 작성하는 프로그램에 주로 신경을 써야 했고, 딱히 도메인을 신경쓰지 않고 살았다. 이 것은 취약점 진단을 전문으로 하는 보안 엔지니어가 되고 나서도 마찬가지였다. 웹 어플리케이션의 구현에서 발생하는 취약점에 주로 신경을 썼다. 그러나 또 몇년간의 시간이 흐른 지금, 이제는 인터넷의 기반 중 하나라고 할 수 있는 도메인 네임 시스템 (Domain Name System, DNS) 에 대해서 공부할 필요가 생겼다. 그래서 올해 2021년은 DNS 관련 취약점을 주로 연구했다. DNS만 해도 다양한 종류의 취약점이 있지만 주로 설정 미스에 의해 발생할 수 있는 취약점들을 주로 연구했다. 왜냐하면 설정 미스는 재발하기도 쉽기 때문에, 지속적으로 체크할 필요가 있기 때문이다. 체크 방법을 한번 정리해두면 계속해서 활용할 수 있을 것이다. 연구를 통해 Open Resolver, DNS Zone Transfer, DNS Zone Takeover, DNS Subdomain Takeover, Same Site Scripting 등의 취약점이 도메인 설정 (또는 DNS 서버의 설정) 미스로 발생하는 것을 알았다. 이러한 취약점들이 어떠한 것이고, 어떻게 체크할 수 있는지를 하나씩 정리해 나가고자 한다.
CSP 헤더를 사용하면 자신의 사이트에서 허용할 리소스(스크립트, 이미지, CSS등 등) 의 소스를 제어할 수 있다. 예를 들면, 신뢰할 수 없는 외부로부터의 리소스등이 자신의 사이트(도메인)의 웹 페이지에서 실행되지 않도록 제어할 수 있다. 따라서, XSS 취약점에 대한 유용한 방어책이 된다.
다음 사진은 CSP 헤더에 대한 재미있는 비유이다. CSP 는 XSS 취약점에 대한 최종 방어책이라는 것이다. (참고로 한국의 홍화문을 찍은 사진이다.)
<policy-directive> 는 <directive> <value> 로 구성된다. (directive 와 value 는 스페이스로 구분)
directive (지시자) 는 몇 가지 타입이 있는데,
Fetch directives, Document directives, Navigation directives, Reporting directives, Other directives 가 그 것이다. 주로 많이 보이는 것이 Fetch directives 인데, default-src, connect-src, child-src 등 리소스를 허용할 위치를 지정하는데 쓰이는 지시자들이다.
CSP 헤더 샘플
예를들어 다음은 가장 엄격한 설정의 예이다. 이 설정을 적용하면 스크립트, 이미지, CSS등의 리소스의 출처가 자신의 사이트일 경우만 실행이 허용된다.
아직 CSP 를 적용하지 않은 사이트도 많지만,미국의 빅텍 회사등을 포함한 유명기업들은 CSP 헤더를 적용해서 사이트를 방어하고 있다. 참고로 내가 살펴본 결과에 의하면 github 의 CSP 평가 결과가 거의 완벽했다.
인라인 스크립트
인라인 스크립트는 HTML 페이지안에 자바 스크립트가 포함된 스타일을 의미한다. 프로그래밍 관점에서도 유지보수가 어려워지기 때문제 좋지 않은 스타일이라고 알려져 있지만, 당장 처음에 개발할 때는 쉽기 때문에 아직도 여러 곳에서 쓰이고 있는 것 같다.
CSP 헤더를 적용하려면서 인라인 스크립트를 사용하려면 CSP 헤더에 ‘unsafe-inline’ 속성을 추가해야 한다. 하지만 이 경우, Reflected XSS 처럼 유저의 입력이 웹 페이지에서 출력되어 발생하는 타입의 XSS 를 허용해버리기 때문에 보안 측면에서는 좋지 않다.
따라서, 가능한 한 인라인 스크립트 사용은 지양하는 것이 프로그래밍 측면에서도 보안 측면에서도 좋다고 생각한다.
한편, 이미 너무 많은 사이트에서 인라인 스크립트가 횡행하고 있으므로 인라인 스크립트를 허용하면서도 CSP가 주는 보안이점을 누리기 위한 방법이 개발되었다.
CSP 버전 2에서 도입된 nonce 가 그것이다. nonce라는 것은 일회용 랜덤 값이다. 유저가 인라인 스크립트가 사용된 웹 페이지를 요청하면 웹 서버는 HTTP응답의 CSP 헤더와 해당 페이지의 인라인 스크립트 블록에 nonce 라는 속성을 추가해서 유저에게 응답한다. 웹 브라우저는 nonce 값이 일치할 때에만 리소스를 허용한다. 이렇게 하면 XSS 가 해당 스크립트 블록 안에서 발생하지 않는 이상 안전하다. (유저의 입력이 인라인 스크립트 블록안에 출력되는 경우, 이건 정말 피해야 할 패턴이다.)
또한, 하나하나 nonce 를 추가하는 것이 귀찮은 경우가 있으므로 CSP 버전3에서는 strict-dynamic이 추가되었다.
CSP 헤더 해석
CSP 헤더에 설정가능한 지시자는 아주 많은데, 각각 의미를 이해하는데 다음 링크가 도움이 많이 된다.









{kind=link}